
I had the opportunity to teach last month. One of the topics I covered was the cloud as an environment and as a platform. One of the most significant issues I had conveying the information was a general lack of understanding of just what comprises today's platforms and an incomplete understanding of just how it all works. I ended up describing in detail the process of sending data from one machine to another, regardless of whether that machine was a phone or a computer and how it traversed the network, be it cellular or physical cable. I thought this explanation might benefit others.
ISO OSI layer model
Before we can discuss the process, we have to understand our stack. In this case, it is the standard ISO Open Systems Interconnection (OSI) model. The model, from top to bottom, looks like this:
- Layer 7 - Applications Layer
- Layer 6 - Presentation Layer
- Layer 5 - Session Layer
- Layer 4 - Transport Layer
- Layer 3 - Network Layer (sometimes called the routing layer)
- Layer 2 - Data Link Layer (sometimes called the switching layer)
- Layer 1 - Physical Layer
It is essential to understand what happens at each of these layers from a theoretical perspective, especially if you have responsibilities to debug a problem in your environment. It is also essential to recognize that it is a model of how data flows through the system. Certain aspects of the model might be bypassed by specific applicational or protocol purposes. But generally, if you understand this model, the rest of the process will flow from here.
In brief:
Layer 1 - Physical
The physical layer is responsible for the transmission and reception of unstructured raw data between a device and a physical transmission medium such as ethernet (Cat 5/6 copper cable) or any of the various forms of fibre (used in both network and server to data transfers) or coax (used primarily for long haul and building connections). It converts the digital bits into electrical, radio, or optical signals. It is the cables that push data between servers and between servers and storage. Bluetooth can be thought of as a physical layer connection, although it did not exist when the original model was developed. X.25 is one of the earliest protocols developed to support the physical layer.
Layer 2 - Data Link Layer
The data link layer provides node-to-node data transfer—a link between two directly connected nodes. Here we begin to talk about the frames of a data packet and the establishment of both a medium access control (MAC) layer, where devices gain access to the network layer protocols, and the Logical link control (LLC) layer where encapsulation and error checking and frame synchronization begins. This is where we see Ethernet standards applied, WiFi standards, and the old Point-to-Point (PPP) standards appear.
Layer 3 - Network Layer
The network layer provides the functional and procedural means of transferring packets from one node to another connected in different networks, effectively routing packets from one network to another, with intelligence. When we talk about routing protocols, we hear terms like EGIRP (Cisco proprietary) and OSPF. Older protocols include RIP. IPSec also happens at layer 3.
Layer 4 - Transport Layer
The transport layer provides the functional and procedural means of transferring variable-length data sequences from a source to a destination host while maintaining the quality of service functions. We start talking about the size of a data packet in the network (or frame size). The standard for a TCP packet is 1500 bytes in length with a payload of about 32bits of the total frame. Packets larger than this size may be transmitted if all the routers and switches in the network agree to it, but if you are connecting to the Internet, that is all you get. As a result, large data transfers segment their data into many(!) TCP packets.
This layer is also responsible for flow control but not for reliability. That is the responsibility of the protocol. TCP, as a protocol, is chatty. It acknowledges each packet sent and received, thus ensuring reliability. UDP is what we call an unreliable protocol. If something transfers over UDP, there is no guarantee mechanism or message to ensure it arrived successfully.
Layer 5 - Session Layer
This layer is responsible for dialog control. It establishes, manages, and then terminates the connections in either full-duplex, half-duplex, or simplex. This is also where session checkpointing occurs, such as with remote procedure calls (RPCs). As part of this model, the session layer is purely theoretical, and in practice, the Session Layer is integrated into other parts of the TCP/IP stack.
Layer 6 - Presentation Layer
The presentation layer is the context switch between application layer items. This is where mapping occurs (if needed), encapsulation (TLS), or other processes to move data up or down the communication stack.
Layer 7 - Application Layer
This is where the user generally interacts with the application. Where Graphical User Interfaces are drawn and displayed and where input and output occur.
While this is all grossly simplified, it highlights several steps where things can go wrong. Still, it also highlights why you need to know how your application will intersect with the various subsystems below it and what that impact might mean in terms of resource allocation, consumption, and application performance over time.
The Server Farm

The cloud is nothing more than many servers, working together, with or without some form of storage. Technically, today, the cloud is more about the application you are interacting with and less about where the environment the application runs is located or how it is constructed. It is crucial to understand, at least in theory, what the application is doing, where it lives, and why it all works the way it does1.
Companies that provide cloud services (like Amazon Web Services and Microsoft Azure) maintain large data centers, essentially warehouses, filled with equipment. A lot of equipment. Most of this equipment lives in racks nineteen inches across and 42 U (a technical term) in height2.
A typical rack includes:
- The rack (and screws, do not forget the screws)
- A power source (most are DC powered in data centers)
- A rack-based router (for all those servers)3
- The servers (1U - 4U boxes)
The servers will compose most of the space in the rack, so anywhere from 38 servers (at 1U) to 9 servers (at 4U). Large servers tend to be reserved for more specialized purposes, like running database platforms within the environment (think Amazon Redshift or Azure SQLServer).
In other parts of the datacenter, you will find racks dedicated to storage, routing, and other operational requirements (like the Amazon Marketplace) or CI/CD for host management. Most data centers do not run at 100%. At any time, a host (or a rack of them) will be down for maintenance or replacement, hard disks need tending, and wires and cables sometimes need to be repositioned to add more capacity or change it.
But there is still one more layer of abstraction that needs to discuss. It is unlikely you will run your application on a server directly, what we call bare metal. In most cases (all cases for AWS or other commercial cloud vendors), you will run in a virtualized (guest) space on the host OS (the OS on the bare metal). Such hosts include VMWare's vSphere, or Microsoft Hyper-V, or Linux's KVM. Through magical trickery4, the host mirrors the bare metal for the guest OSs and depending on the resources of the bare metal, and you can run multiple guests per server. With shared storage, you can interconnect storage across various hosts. This becomes the power of the cloud.
When is the cloud a platform?
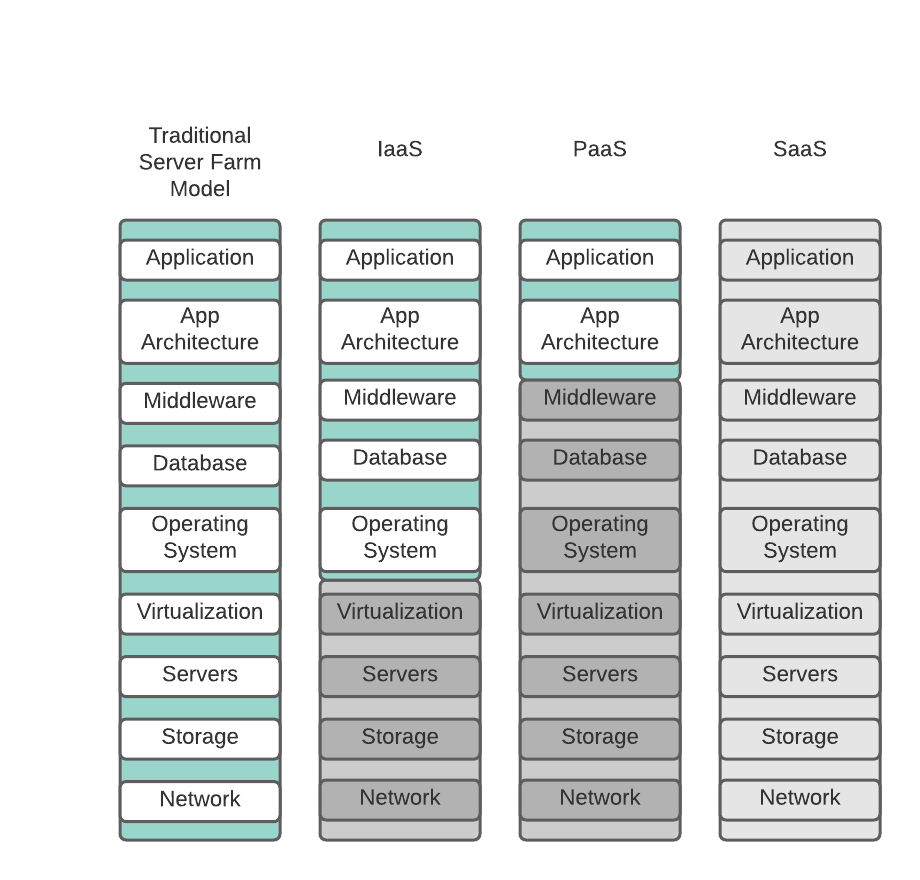
Using the above figure as a reference, up to this point, we have discussed the traditional server farm model, whether that model has all components in a single rack or a series of racks. In this case, you are responsible for managing all aspects of the environment, including the power and cooling you need to keep it functioning, along with the personnel to run it. This is not the cloud.
When we discuss Infrastructure as a Service (IaaS - second column), it becomes a cloud environment. It is at this point where the management of the environment shifts and splits. The company providing the infrastructure (such as Amazon) is responsible for all aspects of that environment up to the (guest) operating system level. From that point onward, the customer is responsible. In most cases, this means they are responsible for the security and patching of the guest and all applications running on and interacting with the guest. This may be a single host (guest) or a whole farm of interconnected hosts with containers, databases, and storage. In essence, you are purchasing traditional (albeit virtual) infrastructure from a provider. The line between cloud and traditional networks is blurred, and it is easy to confuse the two. Just remember, if you are using Infrastructure as a Service, there are still many subsystems you are not managing, nor are you responsible for keeping current.
It becomes a platform when you move into Platform as a Service (PasS). The application is where you interact, and the only responsibility you have is for the application and its associated architecture. Any patches or updates to the OS, the databases, etc., are the cloud provider's responsibility. It may require you to adapt your application based on changes in APIs or associated calls to the middleware. Still, those generally are small changes advertised well in advance of any lower-level updates. You can also reduce the skillset you need to have on staff. Typically, you are only developing your application. Most software companies are at this level if they are developing their own applications.
Finally, there is Software as a Service (SaaS). Offerings like Salesforce, Workday, Lucidchart, where you rent application space are SaaS. While you might configure the application or write additional customizations to address gaps, you are not responsible for the underlying platform or application. Updates are delivered to you, with warnings when there are systemic changes you need to account for or prepare for, but you are renting the application and using your data at the end of the day. As the consumer, you do not have to do anything.
Moving the data
One of the reasons for the success of the Internet is the ability to move data from here to there through standard, well-understood protocols. Before the 1990s, most of this was via dedicated communication lines between universities and certain federal agencies. These systems were almost always Unix-based and utilized TCP/IP as the communications protocol. Tim Berners-Lee had not developed the HTTP protocol for sharing documents, no Google for finding sites, and there certainly was not enough bandwidth for video streaming, much less the codecs. Any data transferred went via FTP or email, and security was not high on the list of essential items. Most people had never heard of the Internet. That all changed and rapidly throughout the 1990s and early 2000s.
But there was still the limitation of the physical cable, whether that was in the data center, the business office, or the connection between the house computer and the Internet Service Provider (ISP). Firms like AOL, Compuserve, and Prodigy were the first access (the on-ramps) to the information super highway. Often they came with additional protections and filters that kept people from the bad parts of the Internet. In the middle part of the 1980s, the FCC released the 2.5 GHz bandwidth space for general use (the same frequency range used by microwave ovens and today's 5G). However, it was not until the late 1990s that the first reliable WiFi interfaces were released for public use, primarily by corporations rather than home users.
At the same time, we begin to see high speed, high capacity, high bit rate lines deployed between central offices and the ISPs. Dedicated (T1 & T3) and fractional (Frame Relay, ATM) connections connected business offices to the main office and flowed through increasing large, complicated telco clouds. This further increased the concentration of data within the telco networks.
All of this would be required for the next quantum leap forward - the movement (and capability) to use mobile devices connected to the cellular network. It would take another discussion to cover the technology in the cellular network but go back to our basics. The mobile device is connected to the cell tower, where it gets an IP address (IPv6 in case you are wondering, and that is yet another discussion). Data is then encapsulated on the phone and sent up the wire (cell connection) to the tower, where it is received, translated into bits, and sent to the network. The cell tower acts as part of the physical layer. Modern-day mobile equipment is no different from your laptop or desktop in terms of networking software. Because of this, we are seeing the convergence of mobile and desktop operating systems at a speed that eclipses their initial development.
Conclusion
There are many areas of this process that have been glossed over for complexity sake. For example, the whole discussion of a TCP packet takes up three volumes, starting with TCP/IP Illustrated, Volume 1: The Protocols. Routing and switching is a skill set of its own, and storage management is a full-time job. Then there are the aspects of database management, cellular RF engineering, and the headaches of making good fibre connections (hint, polishing glass is tricky to master).
But with this overview, you should begin to understand the levels of responsibility, and more importantly, the amount of complexity that has been engineered out of the system, primarily if you work at the platform level. Clouds are not free. There is a great deal of work and costs in keeping them operational, even if you are not the one doing it.
Web Links:
- In many cases, the location where your application is running or the data is residing is not an issue, but remember that the cloud, especially for large cloud providers, could have data stored in locations that may have legal ramifications for that data. ↩
- We call them 19" racks because of the internal space between the screw holes that hold the equipment in place. The outer dimensions of each rack generally are two feet wide by as much as two feet deep, but most servers stick out another foot or so beyond that. Rack as measured in how many rack units high (a rack unit is 1-3/4 inches) and defines how much equipment it can hold. ↩
- These are often called Layer 3 switches, which combine the features of a Layer 2 switch functionality and the routing capabilities of a traditional router. ↩
- We could spend another hour discussing the various coding games played by the kernel and the requirements in the CPU for virtualization to work. ↩